Sortowanie kubełkowe
 | |
| Rodzaj | |
|---|---|
| Struktura danych | |
| Złożoność | |
| Czasowa |
|
| Pamięciowa |
|


Sortowanie kubełkowe (ang. bucket sort) – jeden z algorytmów sortowania, najczęściej stosowany, gdy liczby w zadanym przedziale są rozłożone jednostajnie, ma on wówczas złożoność Θ(n)[1]. W przypadku ogólnym pesymistyczna złożoność obliczeniowa tego algorytmu wynosi O(n²).
Pomysł takiego sortowania podali po raz pierwszy w roku 1956 E. J. Issac i R. C. Singleton[2].
Sposób działania
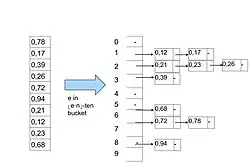
Idea działania algorytmu sortowania kubełkowego[1]:
- Podziel zadany przedział liczb na k podprzedziałów (kubełków) o równej długości.
- Przypisz liczby z sortowanej tablicy do odpowiednich kubełków.
- Sortuj liczby w niepustych kubełkach.
- Wypisz po kolei zawartość niepustych kubełków.
Zazwyczaj przyjmuje się, że sortowane liczby należą do przedziału od 0 do 1 - jeśli tak nie jest, to można podzielić każdą z nich przez największą możliwą (jeśli znany jest przedział) lub wyznaczoną. Należy tu jednak zwrócić uwagę, że wyznaczanie największej możliwej liczby w tablicy m-elementowej ma złożoność obliczeniową O(m).
Pseudokod
Algorytm sortowania kubełkowego wyrażony w pseudokodzie[3]:
function bucket-sort(array, n) is
buckets ← new array of n empty lists
for i = 0 to (length(array)-1) do
insert array[i] into buckets[msbits(array[i], k)]
for i = 0 to n – 1 do
next-sort(buckets[i])
return the concatenation of buckets[0], ..., buckets[n-1]
Przypisy
- 1 2 Cormen i in. 2007 ↓, s. 215.
- ↑ Samanta Debasis 2009 ↓, s. 643.
- ↑ Cormen i in. 2007 ↓, s. 215-216.