Duży model językowy
Duży model językowy (ang. large language model, LLM)[1] – model sztucznej inteligencji umożliwiający generowanie tekstu oraz realizację zadań związanych z przetwarzaniem języka naturalnego. Modele LLM są szkolone w ramach samonadzorowanego lub słabo nadzorowanego uczenia maszynowego z wykorzystaniem dużych ilości danych tekstowych. Proces ten jest intensywny obliczeniowo[2]. Duże modele językowe mogą być wykorzystywane do generowana tekstu poprzez wielokrotne przewidywanie następnego tokenu lub słowa, przez co zaliczane są do generatywnej sztucznej inteligencji[3].
Duże modele językowe są sieciami neuronowymi. Największe i najbardziej zdolne modele językowe oparte są na architekturze transformerów.
Przykładami dużych modeli językowych są modele z serii GPT zbudowane przez OpenAI (np. GPT-3.5, GPT-4), używane w chatbotach ChataGPT i Microsoft Copilot, a także modele Llama zbudowane przez Meta Platforms. Istnieją również chińskie modele jak DeepSeek czy polskie jak Bielik i PLLuM.
Historia
Przed rokiem 2017 istniało kilka modeli językowych, które — jak na ówczesne możliwości — były uważane za duże. W latach 90. modele IBM pozwoliły na rozwinięcie się metod statystycznego modelowania języka. W 2001 roku model bazujący na n-gramach został wytrenowany na 300 milionach słów[4]. W latach dwutysięcznych, wraz z popularyzacją Internetu, rozpoczęto tworzenie zbiorów językowych o skali porównywalnej z Internetem[5], na bazie których podjęto próby uczenia statystycznych modeli językowych[6][7].
Po tym, jak sieci neuronowe stały się popularne w przetwarzaniu obrazów około 2012 roku[8], zaczęto je również stosować do przetwarzania tekstu. W 2016 roku Google wprowadziło w Tłumaczu Google swój model językowy oparty na głębokiej sieci LSTM.
_vs_Publication_date_(2017-2024).svg.png)
W 2017 roku naukowcy z Google zaproponowali architekturę transformatora[9] opartą na mechanizmie uwagi opracowanym w 2014 roku[10]. W 2018 roku Google wypuściło model BERT oparty wyłącznie na koderach transformatora[11][12]. Od 2023 roku akademickie i badawcze zainteresowanie BERT-em zaczęło stopniowo maleć na rzecz modeli opartych na dekoderach transformatora jak GPT[13].
Od 2022 roku zyskują na popularności modele o otwartym kodzie źródłowym – początkowo za sprawą projektów takich jak BLOOM[14] i Llama, choć oba objęte są ograniczeniami dotyczącymi zakresu zastosowań. Modele Mistral AI udostępnione zostały na bardziej liberalnej licencji Apache. W styczniu 2025 roku firma DeepSeek wypuściła w formie otwartego kodu model DeepSeek R1, mający 671 miliardów parametrów. Jego wydajność jest porównywalna z modelem OpenAI o1, przy znacznie niższych kosztach eksploatacji[15].
Od 2023 roku wiele modeli ma charakter multimodalny, co oznacza, że potrafią analizować i generować różne typy danych, takie jak tekst, obrazy czy dźwięk[16].
W roku 2024 największe i najbardziej zaawansowane modele językowe oparte są na architekturze transformatora. Niektóre nowsze implementacje wykorzystują jednak inne podejścia, takie jak rekurencyjne sieci neuronowe (RNN) czy architektura Mamba[17].
Trenowanie i architektura
Wzmacnianie z informacją zwrotną od człowieka
Uczenie się przez wzmacnianie z informacją zwrotną od człowieka (RLHF) to metoda umożliwiająca dostosowanie działania modelu językowego do ludzkich oczekiwań. Preferencje użytkowników definiuje się poprzez trenowanie tzw. modelu nagród, który następnie służy do dalszego uczenia modelu językowego z wykorzystaniem algorytmów uczenia przez wzmacnianie takich jak proximal policy optimization (PPO)[18].
Mieszanka ekspertów
Największe modele językowe bywają zbyt kosztowne w trenowaniu i bezpośrednim zastosowaniu. Dlatego coraz częściej stosuje się podejście mieszanki ekspertów (ang. Mixture of Experts, MoE)[19][20][21]. MoE to technika, która dzieli przestrzeń problemu między wiele wyspecjalizowanych sieci przez co inferencja aktywuje tylko te części sieci, które są najbardziej odpowiednie[22], a sama metoda jest zaliczana do metod uczenia zespołowego[23].
Dostrajanie na podstawie instrukcji
Duże modele językowe uczą się generować poprawne odpowiedzi i zastępować naiwne uzupełnienia dzięki kilku wstępnym korektom wprowadzonym przez człowieka oraz zastosowaniu podejścia self‑instruct. Na przykład w odpowiedzi na polecenie: „Napisz esej na temat głównych motywów przedstawionych w Hamlecie” model mógłby najpierw wygenerować: „Jeśli oddasz esej po 17 marca, Twoja ocena zostanie obniżona o 10% za każdy dzień opóźnienia”, bazując na częstotliwości takiego ciągu w korpusie[24].
Koszt
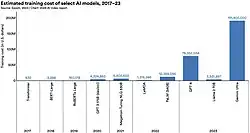
Trenowanie i działanie dużych modeli językowych zazwyczaj wymaga ogromnej mocy obliczeniowej i zużycia energii, co rodzi pytania dotyczące wpływu na środowisko[25][26].
Rozumowanie
Pod koniec 2024 roku w rozwoju dużych modeli językowych pojawił się nowy kierunek, skoncentrowany na zadaniach wymagających złożonego rozumowania. Modele tego typu, określane jako „modele rozumujące”, zostały wytrenowane tak, aby poświęcać więcej czasu na generowanie rozwiązań krok po kroku (ang. chain-of-thought) przed udzieleniem odpowiedzi końcowej – w sposób zbliżony do ludzkiego procesu rozwiązywania problemów[27]. Trend ten zapoczątkowała firma OpenAI, wprowadzając we wrześniu 2024 roku model o1[27], a następnie model o3 w grudniu 2024[28]. W porównaniu z tradycyjnymi LLM-ami, nowe modele wykazywały znaczną poprawę wyników w zadaniach z matematyki, nauk ścisłych oraz programowania. Przykładowo, na zadaniach z eliminacji do Międzynarodowej Olimpiady Matematycznej model GPT-4o uzyskał 13% skuteczności, podczas gdy model o1 osiągnął aż 83%[28].
W styczniu 2025 roku chińska firma DeepSeek przedstawiła model DeepSeek‑R1 — model rozumowania o otwartych wagach, posiadający 671 miliardów parametrów, który osiągnął wyniki porównywalne do modelu o1 firmy OpenAI, przy znacznie niższych kosztach operacyjnych. W przeciwieństwie do zastrzeżonych modeli OpenAI, otwarta architektura DeepSeek‑R1 umożliwiła badaczom analizę i dalszy rozwój algorytmu, choć dane treningowe pozostały nieupublicznione[29].
Tego typu podejście z reguły mają większe wymagania obliczeniowe w porównaniu z bezpośrednim podejściem ponieważ model musi generować wiele odpowiedzi dla każdego kroku jednak pozwala to na osiągnięcie lepszych wyników w dziedzinach wymagających myślenia domenowego[28]. Aby zmniejszyć ilość występowania halucynacji, stosowane są dodatkowe techniki jak automatyczne rozumowanie, RAG czy dostrajanie[30].
Oddziaływanie
Istnieją opinie twierdzące, że nie ma możliwości rozróżnienia tekstu stworzonego przez duży model językowy i przez człowieka[31]. Goldman Sachs w 2023 roku twierdził, że LLM-y są w stanie zwiększyć globalne PKB o 7% w ciągu dekady i bedą potrafiły wystawić na automatyzację pracę 300 mln osób[32][33].
Prawa autorskie
W roku 2023, do sądów w Stanach Zjednoczonych wpłynęło kilka wniosków podważających używanie danych chronionych prawem autorskim do trenowania modeli językowych z obrońcami opierającymi się na instytucję fair use[34].
Bezpieczeństwo
Duże modele językowe mogą być używane do tworzenia dezinformacji, w sposób świadomy lub nie lub do innych celów[35]. Dostępność dużych modeli językowych może pozwolić na obniżenie poziom umiejętności wymaganych do popełnienia czynów bioterroryzmu[36].
Dodatkowo, istnieje możliwość osadzenia uśpionych inteligentnych agentów, czyli ukrytych funkcjonalności, które w normalnych warunkach nie wykonują akcji, a po uzyskaniu impulsu aktywującego, rozpoczynają wykonywania szkodliwych działań[37].
Aplikacje LLM zawierają odpowiednie filtry moderacyjne jednak nie są one w pełni efektywne i pozwalają na wykorzystanie jako technologia podwójnego zastosowania[38] czy różnych nielegalnych operacji[39].
Stronniczość algorytmiczna
Podczas gdy duże modele językowe są w stanie generować tekst przypominający ludzki, są skłonne do dziedziczenia i powiększania stronniczości zawartej w danych testowych. Stronniczość może się objawiać w błędnym i niesprawiedliwym traktowaniu różnych grup demograficznych[40].
Zobacz też
Przypisy
- ↑ A short history of AI. „The Economist”, s. 56, 20th July 2024.
- ↑ OpenAI: Better language models and their implications. [dostęp 2024-05-08]. [zarchiwizowane z tego adresu (2020-12-19)].
- ↑ Czym jest generatywna sztuczna inteligencja? | Deloitte [online], Deloitte Polska [dostęp 2024-05-08] (pol.).
- ↑ Joshua Goodman, A Bit of Progress in Language Modeling, arXiv, 9 sierpnia 2001, DOI: 10.48550/arXiv.cs/0108005 [dostęp 2025-04-11].
- ↑ Adam Kilgarriff, Gregory Grefenstette, Introduction to the Special Issue on the Web as Corpus, „Computational Linguistics”, 29 (3), 2003, s. 333–347, DOI: 10.1162/089120103322711569, ISSN 0891-2017 [dostęp 2025-04-11].
- ↑ Michele Banko, Eric Brill, Scaling to very very large corpora for natural language disambiguation, ACL '01, USA: Association for Computational Linguistics, 6 lipca 2001, s. 26–33, DOI: 10.3115/1073012.1073017 [dostęp 2025-04-11].
- ↑ Philip Resnik, Noah A. Smith, The Web as a Parallel Corpus, „Computational Linguistics”, 29 (3), 2003, s. 349–380, DOI: 10.1162/089120103322711578, ISSN 0891-2017 [dostęp 2025-04-11].
- ↑ Chen i inni, Review of Image Classification Algorithms Based on Convolutional Neural Networks, „Remote Sensing”, 13 (22), 2021, DOI: 10.3390/r, ISSN 2072-4292 [dostęp 2025-04-11] [zarchiwizowane z adresu 2025-03-07] (ang.).
- ↑ Vaswani i inni, Attention is All you Need [online], Advances in Neural Information Processing Systems. 30. Curran Associates, Inc, 2017 (ang.).
- ↑ Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio, Neural Machine Translation by Jointly Learning to Align and Translate, arXiv, 19 maja 2016, DOI: 10.48550/arXiv.1409.0473 [dostęp 2025-04-11].
- ↑ Jacob Devlin i inni, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv, 24 maja 2019, DOI: 10.48550/arXiv.1810.04805 [dostęp 2025-04-15].
- ↑ Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processin [online], research.google [dostęp 2025-04-15] (ang.).
- ↑ Rajiv Movva i inni, Topics, Authors, and Institutions in Large Language Model Research: Trends from 17K arXiv Papers, arXiv, 28 kwietnia 2024, DOI: 10.48550/arXiv.2307.10700 [dostęp 2025-04-11].
- ↑ bigscience/bloom · Hugging Face [online], huggingface.co [dostęp 2025-04-11].
- ↑ Shubham Sharma, Open-source DeepSeek-R1 uses pure reinforcement learning to match OpenAI o1 — at 95% less cost [online], VentureBeat, 20 stycznia 2025 [dostęp 2025-04-11] (ang.).
- ↑ Dr Tehseen Zia, Unveiling of Large Multimodal Models: Shaping the Landscape of Language Models in 2024 [online], Unite.AI, 8 stycznia 2024 [dostęp 2025-04-11] (ang.).
- ↑ Dr Tehseen Zia, Unveiling of Large Multimodal Models: Shaping the Landscape of Language Models in 2024 [online], Unite.AI, 8 stycznia 2024 [dostęp 2025-04-11] (ang.).
- ↑ Long Ouyang i inni, Training language models to follow instructions with human feedback, arXiv, 4 marca 2022, DOI: 10.48550/arXiv.2203.02155 [dostęp 2025-04-11].
- ↑ Noam Shazeer i inni, Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, arXiv, 23 stycznia 2017, DOI: 10.48550/arXiv.1701.06538 [dostęp 2025-04-11].
- ↑ Dmitry Lepikhin i inni, GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, arXiv, 30 czerwca 2020, DOI: 10.48550/arXiv.2006.16668 [dostęp 2025-04-11].
- ↑ More Efficient In-Context Learning with GLaM [online], research.google [dostęp 2025-04-11] (ang.).
- ↑ Tara Baldacchino i inni, Variational Bayesian mixture of experts models and sensitivity analysis for nonlinear dynamical systems, „Mechanical Systems and Signal Processing”, 66, 2016, s. 178–200, DOI: 10.1016/j.ymssp.2015.05.009, ISSN 0888-3270 [dostęp 2025-04-11].
- ↑ Pattern Classification Using Ensemble Methods | Series in Machine Perception and Artificial Intelligence, www.worldscientific.com, DOI: 10.1142/7238#t=aboutbook [dostęp 2025-04-11] (ang.).
- ↑ Yizhong Wang i inni, Self-Instruct: Aligning Language Models with Self-Generated Instructions, arXiv, 25 maja 2023, DOI: 10.48550/arXiv.2212.10560 [dostęp 2025-04-11].
- ↑ Large Language Model (LLM)? - FEB [online], feb.net.pl [dostęp 2025-02-13].
- ↑ Anna Klee-Bylica, Czy wiesz, jak dużo energii potrzebuje sztuczna inteligencja? [online], Zielony blog WSIiZ, 16 maja 2024 [dostęp 2025-02-13].
- 1 2 Introducing OpenAI o1 [online], openai.com [dostęp 2025-04-11] (ang.).
- 1 2 3 Cade Metz, OpenAI Unveils New A.I. That Can ‘Reason’ Through Math and Science Problems, „The New York Times”, 20 grudnia 2024, ISSN 0362-4331 [dostęp 2025-04-11] (ang.).
- ↑ Elizabeth Gibney, China’s cheap, open AI model DeepSeek thrills scientists, „Nature”, 638 (8049), 2025, s. 13–14, DOI: 10.1038/d41586-025-00229-6, ISSN 1476-4687 [dostęp 2025-04-11] (ang.).
- ↑ Belle Lin, Why Amazon is Betting on ‘Automated Reasoning’ to Reduce AI’s Hallucinations, „Wall Street Journal”, 5 lutego 2025, ISSN 0099-9660 [dostęp 2025-04-11] (ang.).
- ↑ Prepare for truly useful large language models, „Nature Biomedical Engineering”, 7 (2), 2023, s. 85–86, DOI: 10.1038/s41551-023-01012-6, ISSN 2157-846X [dostęp 2025-04-11] (ang.).
- ↑ Your job is (probably) safe from artificial intelligence, „The Economist”, ISSN 0013-0613 [dostęp 2025-04-11].
- ↑ Generative AI could raise global GDP by 7% [online], www.goldmansachs.com (ang.).
- ↑ Artificial Intelligence Copyright Challenges in US Courts Surge [online], natlawreview.com [dostęp 2025-04-11] (ang.).
- ↑ Davey Alba, AI chatbots have been used to create dozens of news content farms [online], The Japan Times, 1 maja 2023 [dostęp 2025-04-11] (ang.).
- ↑ Could chatbots help devise the next pandemic virus? [online], www.science.org [dostęp 2025-04-11] (ang.).
- ↑ Evan Hubinger i inni, Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training, arXiv, 17 stycznia 2024, DOI: 10.48550/arXiv.2401.05566 [dostęp 2025-04-11].
- ↑ Daniel Kang i inni, Exploiting Programmatic Behavior of LLMs: Dual-Use Through Standard Security Attacks, arXiv, 11 lutego 2023, DOI: 10.48550/arXiv.2302.05733 [dostęp 2025-04-11].
- ↑ Encryption Based Covert Channel for Large Language Models [online], IACR ePrint 2024/586, 2024.
- ↑ Chris Stokel-Walker, ChatGPT Replicates Gender Bias in Recommendation Letters [online], Scientific American [dostęp 2025-04-11] (ang.).
Linki zewnętrzne
- Large Language Models explained briefly. 3Blue1Brown 2024-11-20. [dostęp 2025-02-16].